Introduction
Apache Spark is an open-source distributed general-purpose cluster computing framework with (mostly) in-memory data processing engine that can do ETL, analytics, machine learning and graph processing on large volumes of data at rest (batch processing) or in motion (streaming processing) with rich concise high-level APIs for the programming languages: Scala, Python, Java, R, and SQL.
As Spark a distributed process engine, it follows the Master-Salve architecture. For every Spark application, it creates one Master process and multiple Slave processes. In Spark terminology, the Master is the Driver, and the Slaves are the Executors. The Driver is responsible for analyzing, distributing, scheduling and monitoring work across the execution, as well as maintaining all necessary information during the lifetime of the application. On the other hand, the Executors are only responsible to execute the code assigned to them by the Driver and report back the status back to the Drive.
While the executors have to be run on the cluster machine, we have the option to start the driver on a client machine (local machine) or within the cluster itself. This can be specified by execution mode, i.e. Client Mode and Cluster Mode, respectively. Client Mode is good for application development while Cluster Mode is good for production. However we are not going into the details of these two modes and Spark architecture in this article.
There is a third option to execute a spark job, the Local Mode, which what this article foucs on. When you don't have enough infrastructure to create a multi-node cluster but you still want to set up Spark for simple exploratory work or learning purpose, Local Mode is a ideal. It is the most convenient to start a Spark application. You just need a local machine (e.g. your laptop, an EC2 instance), no resource management (e.g. YARN, Mesos) is required. It begins with a JVM, and everything else including the driver and the executors run inside the same JVM.
There are two methods to execute a spark job (Note that this is different than the modes that we described above).
- Interactive Clients (e.g. Scala shell, PySpark Shell, Jupyter notebook).
- Submit a Spark job using spark-submit utility.
We will mainly talk about the interactive Clients here and will talk about the other one later. Now let's set up the spark environment in Local Mode.
Step-by-Step Guide
Download and Install JDK
As mentioned previously, Local Mode runs everything in JVM, so installing JDK (JAVA development kit) is required for the local machine. First, check if your local machine has already installed JDK by running java -version in the terminal. If nothing shows up, it means JDK is not yet installed. You can download the JDK compatible with your system from here (Spark currently only supports Java 8, see SPARK-24417):
Once installed successfully, you should see something like this
$ java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
Download and Install Apache Spark
Install the latest (2.3.0) Apache Spark from https://spark.apache.org/downloads.html. You just can manually download the tgz file and then extract it to a location as the spark home. For example
$ wget -c https://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz .
...
spark-2.3.0-bin-hadoop2.7.tgz 100%[===============================================>] 215.65M 6.15MB/s in 40s
...
Total wall clock time: 41s
Downloaded: 1 files, 216M in 40s (5.34 MB/s)
mkdir spark
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C ~/spark2.3/
And then export the environment variableSPARK_HOME, which is the path to the installation location of Spark. In my example, I add the following in my .bash_profile (or .bashrc),
# Spark Home
SPARK_HOME=/Users/pjhuang/spark2.3/spark-2.3.0-bin-hadoop2.7
export SPARK_HOME
Access Spark from Spark/PySpark Shell
Now you have all necessary pieces to use Spark in your local machine. You can start the spark shell using Scala by running spark-shell , or PySpark shell using Python by running pyspark.
$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.0.22:4040
Spark context available as 'sc' (master = local[*], app id = local-1532998304215).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
You can run interactive code in the spark shell using Scala, for example
scala> val x = Array(1, 2, 3, 4, 5)
x: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val x_rdd = sc.parallelize(x)
x_rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
scala> x_rdd.filter(_ % 2 == 0).collect()
res0: Array[Int] = Array(2, 4)
Similarly, you can run python code in a PySpark shell.
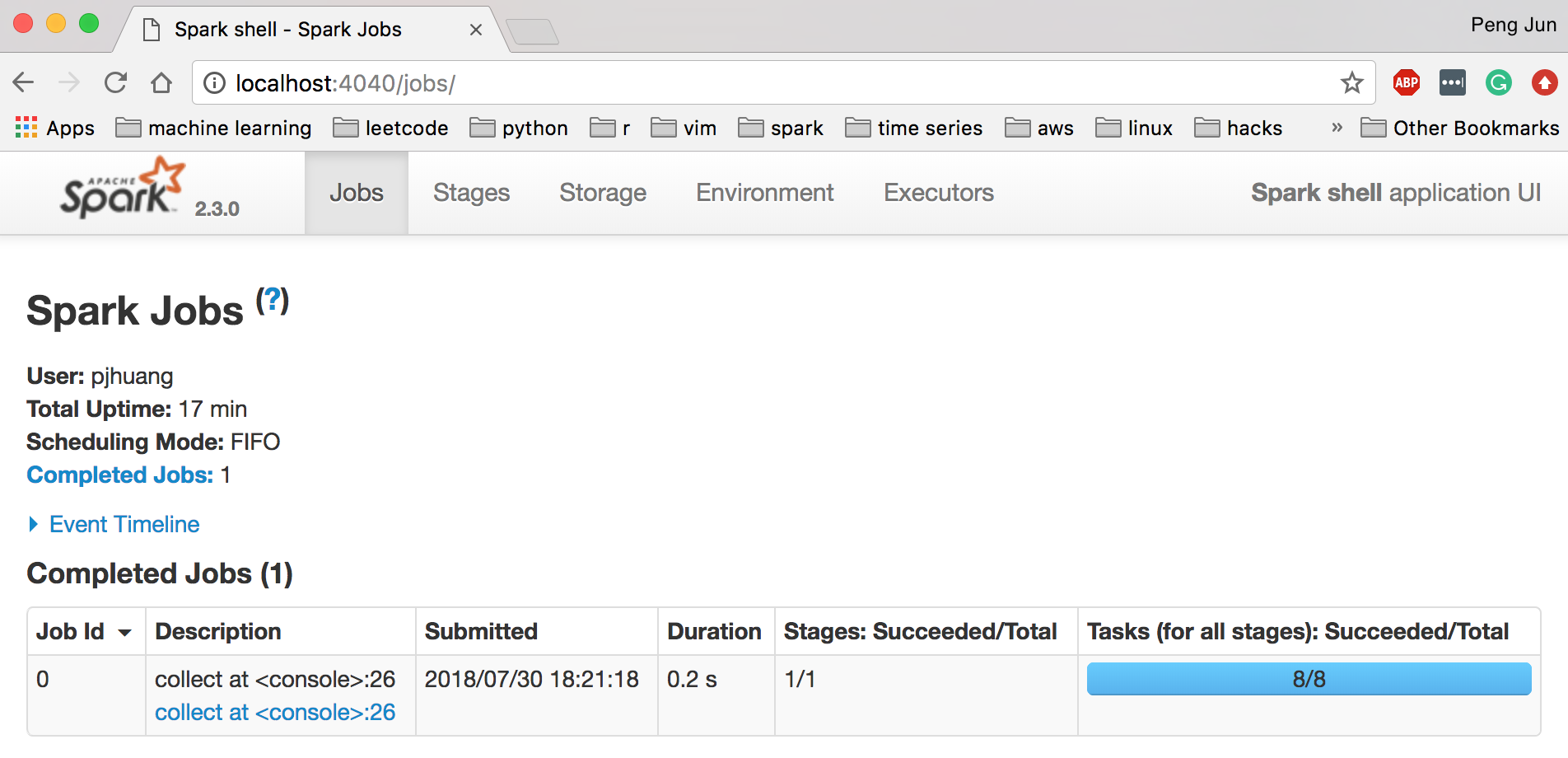
Spark provides a nice web UI to monitor applications. The link is shown in the message when creating the shell (http://192.168.0.22:4040 or localhost:4040). You can find most information about your running and historical spark applications in a Driver. I won't go into the details of the UI here, but you can go through Apache Spark application visualization tutorial if you are interested.
Access Spark from Jupiter Notebook with Apache Toree
Using Spark shell may not be the most efficient IDE for exploratory work and development. We can run Spark using Jupyter Notebook just like we run interactive python code there. However, Jupyter doesn't come with Spark kernel by default, so we have to set up one ourselves. This repo has a list of comprehensive Jupyter kernels available. For Spark kernels, I would recommend Toree, but feel free to use others if you want. For Toree, you can download the 2.0 version , which works with Spark 2, from the open source (repo). Follow the instruction in install section to dowanload the tar.gz file and then use pip install to install.
pip install toree-0.2.0.tar.gz
Finally, install Toree to Jupyter and configure interpreters. For example, I configure Scala, Pyspark, and SQL using the following command
jupyter toree install --spark_home=$SAPRK_HOME --interpreters=Scala,PySpark,SQL
You can start your jupyter notebook as usual, and you will see the installed interpreters are available. Now you can develop and run spark code interactively!
If you run your Jupyter notebook in on a remote machine, e.g. an EC2 instance, you may need to set up SSH tunnel to view the Spark web UI and Jupyter notebook. If you don't know how to do so, I will let you figure it out :)
Conclusion
Above summarizes basic instruction about how to set up an environment of Apache Spark in Local Mode, which I think is very useful for exploratory analyses and learning purpose. Spark is a powerful tool in both data science and software engineering field, and it has a big and active community, and is under fast development. You can see it being used anywhere widely in the in the industry nowadays. Mastering Spark or even just being familiar with it is definitely a great skill to have. I hope this article is helpful.
Leave your comments below.